


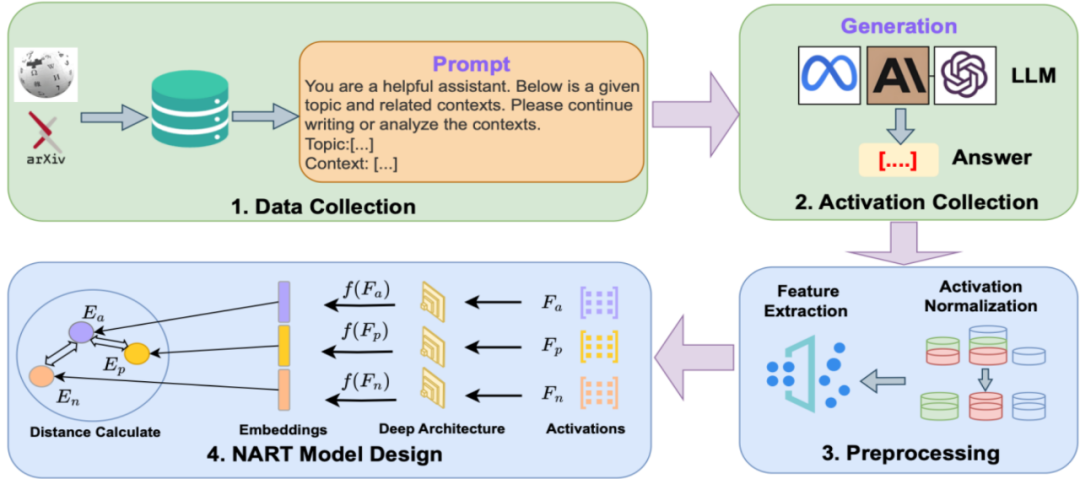
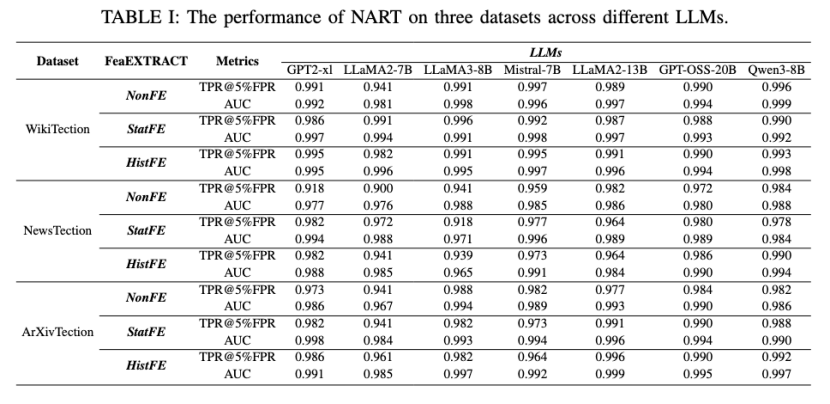
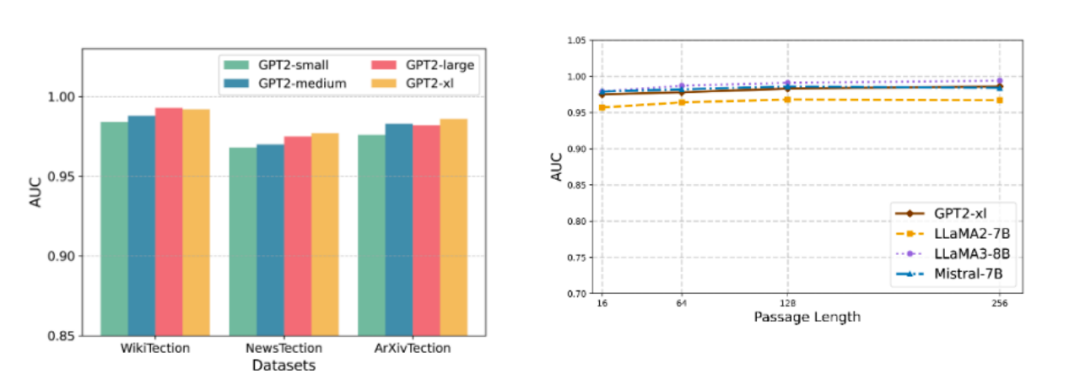
针对开源大语言模型(LLMs)训练数据不透明引发的隐私与版权风险,本文提出了一种名为 NART 的白盒成员推理攻击方法 。研究团队构建了 WikiTection、NewsTection以及ArXivTection 等三个基于时间切片的动态基准数据集,以规避数据泄露干扰 。不同于传统依赖输出概率的方法,NART 提取模型全层神经元的激活值,通过三种特征提取策略(NonFE, StatFE, HistFE)捕获内部知识表征,并利用基于孪生网络架构的三元组网络在特征空间中优化成员与非成员样本的距离 。实验显示,该方法在 GPT-2、LLaMA、Mistral、Qwen等多种异构模型上均表现出优越的性能,且在面对文本改写、模型量化及小样本场景下表现出极强的鲁棒性。这项工作深刻揭示了当前大模型因内部表征的静态确定性与结构单一性而存在的内生脆弱点,凸显了构建具备动态异构与冗余特性的内生安全防御体系对于抵御此类深度白盒成员推理攻击的必要性。
论文信息
相关论文已经被Network and Distributed System Security Symposium (NDSS-2026) 录用。作者系复旦大学大数据研究院内生安全实验室的谭学、栾昊、骆明宇、余柱阳、陈平(通讯作者),以及伍斯特理工学院的戴军(通讯作者)、孙晓燕(通讯作者)
Xue Tan, Hao Luan, Mingyu Luo, Zhuyang Yu, Ping Chen, Jun Dai, Xiaoyan Sun. Was My Data Used for Training? Membership Inference in Open-Source LLMs via Neural Activations. Network and Distributed System Security Symposium (NDSS-2026)

