

近年来,军事对抗已经逐渐从物理空间扩展到认知空间,由人的精神和心理活动构成的认知域正成为新的战场,成为军事斗争和战略博弈的新领域。从本质上讲,今天人们所说的认知域,是由人类智能和人工智能系统共同构建起来的虚实结合的新空间,“人、机、智”在这里共融共生,“物理—信息—认知”三个空间相互交织。在认知域中,人工智能系统是纽带和桥梁。没有人工智能系统,认知域可能还处于形而上、虚无缥缈的状态。人工智能系统作为人造系统,必然存在脆弱性,必然存在内生安全问题。在认知域对抗中,如何构建人工智能内生安全新范式?如何建设可用、可靠、可信以及更可持续发展的技术?如何建立认知空间的安全屏障?为此,记者专门采访了复旦大学大数据研究院陈平研究员,共同探讨认知域安全问题。
人工智能存在内生安全问题
目前,世界各国都高度重视人工智能技术的发展,纷纷推进人工智能的规模化应用。与此同时,人工智能的安全风险也日益凸显。陈平研究员指出,人工智能技术存在内生安全问题,也就是由其基础理论体系的不完备性而导致的内源性安全风险。打个比方,例如十九世纪物理学出现的“两朵乌云”一样,人工智能技术也同样存在“两朵乌云”。

图为在郑州网络安全科技馆展现的基于自动驾驶平台的人工智能对抗演示系统
(王丹玉 供图)
首先是人工智能的不可解释性带来的安全风险。人工智能技术所依赖的机器学习算法,本质上是通过给定的大量数据,训练学习模型对信息进行判定,“葫芦依样”地对数据进行分类,稍有不慎就可能“画虎不成反类狗”,落个“东施效颦”的结果。比如,攻击者可以将一堆树懒的照片标记为猫,这一小群“有毒”的数据样本很有可能诱使系统在被要求展示小猫时出现树懒照片。据有关材料显示,这种“数据投毒”的攻击方式,已经变得越来越容易。研究人员只需要通过毒害不到0.7%的提交给机器学习系统的数据,就能让人工智能系统做出错误的判断。这意味着只需要几个恶意样本,就能够让人工智能做出误判。与此同时,越来越多成熟的人工智能技术被用于制造虚假信息,深度伪造视频、音频、图像、文本。据兰德公司的报告显示,一种新的深度伪造虚假信息的0—day风险正在出现,攻击者通过开发一个定制的生成模型来创建可绕过检测的深度伪造内容,令现在的所有检测手段变得脆弱。数据投毒、深度伪造,这些问题将会严重干扰人们的个体认知,甚至会操控社会认知、影响群体认知,进而对国家安全带来新的威胁。
另一个问题,就是人工智能模型的漏洞后门问题。大数据、大算力、大模型,被称为今天驱动人工智能技术发展的“三驾马车”。因为大模型的出现,人工智能的发展又进入了一个新的阶段。但是,目前大部分先进的模型都使用开源代码框架进行调试部署,这些框架普遍存在安全漏洞。早在 2017年,美国佐治亚大学、弗吉尼亚大学等院校就发现 TensorFlow、Caffe 和Torch 等3个平台有 15 个漏洞,类型包括拒绝服务攻击等等。根据开源软件社区GitHub数据显示,2020 年以来,Tensorflow 被曝出安全漏洞100余个。其中,百度安全团队发现了75 个可导致系统不稳定、数据泄漏、内存破坏等问题的安全漏洞;360 公司发现 49 个。近期,有关机构对国内外主流开源 AI 框架进行了安全性评测,累计 7 款机器学习框架被发现漏洞 150 多个,框架供应链漏洞 200 多个。据统计,我国现有深度神经网络模型中有80%的以上模型使用的是国外平台,这些开发平台均被曝出存在较多安全漏洞,其潜在的风险将会导致出现系统不稳定、数据泄漏等安全问题。在一定条件下,攻击者还可以实现远程代码执行,直接控制目标系统。陈平研究员告诉记者,漏洞和后门作为人工智能系统的内生安全缺陷,会被攻击者有目的地利用,将成为认知域作战中“心腹大患”。
构建认知域安全的“立体屏障”
陈平研究员告诉记者,面对目前认知域对抗的严峻形势,除了需要解决实时防御、及时侦测、即时响应等基本安全问题,还要从数据安全、算法安全、模型框架安全等三个维度强化认知安全,构建立体化的防御屏障。最近,IBM提出了“三重防护”认知安全免疫系统原型,即安全平台、安全运维、安全威胁数据中心,这对我们强化认知安全很有启发。
从数据安全层面看,攻击者的主要方法是在掌握认知模型的训练数据后,悄无声息的“炮制”出一定量的恶意数据,通过对认知模型实现“投毒”攻击来实现对目标模型的恶意扰动,从而影响认知模型的正确判断。如何保证认知对抗中数据集的安全性,防“投毒”、抗“污染”。陈平研究员认为,可以在认知数据及特征修改、认知模型修改、认知输出等三个不同阶段开展安全防御。对输入数据进行预处理,在第一道“关口”就防止“毒数据”渗透。对训练模型适时剪枝,通过重构学习模型参数、限条件查询等方法来进行数据“投毒”防御。在认知输出的“最后一公里”,增加多模型预测投票、输出结果再处理、联合学习等方法,形成防御闭环。
从算法安全的层面看,人们无法从认知模型的决策过程中发现算法的逻辑错误,导致可能出现算法“偏见”等情况。而在认知领域中,一些带有“偏见”的算法将导致模型作出与实际情况完全不符的决策结果,从而在认知域中造成严重错误,进而在社会面引发一系列连锁反应,其直接损失和间接损失将难以估量。因此,一种基于可解释性的人工智能方法(XAI)正被迫切需求,它可以让人工智能的决策透明化、可信赖化,从而能更好的帮助研究人员优化模型策略,并对外界提供一种可以回溯其分析和决策过程的执行结果。就好比医生问诊,XAI不仅可以让研究人员知道要开哪种“处方药”,更可以让他明白哪些原因是“病因”,哪些现象是“病理”。基于XAI构建的决策算法可以通过回溯其系统的决策过程,来明确系统在各个环节中的决策分析,使其模型变得“可信赖”,并通过专家来进行调整,从而优化系统运行、克服系统“偏见”,加强系统的可信赖程度,确保“言行一致”。
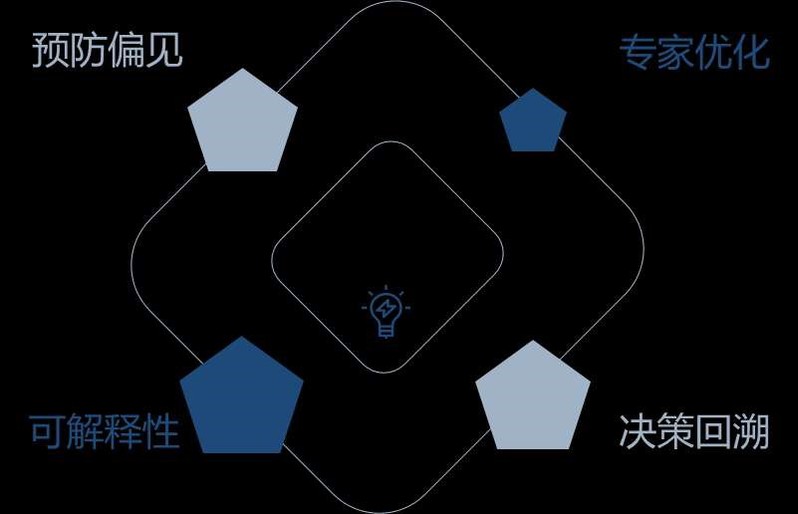
算法安全方法解决方案的概念图(何卓霖 供图)
从训练模型安全的层面看,主要指模型本身存在漏洞,被攻击后将导致不能正常工作,甚至可以利用机器学习的无限敏感性,诱导模型输出错误的结果。为保证训练模型的安全,既需要做到“外练筋骨皮”,加强漏洞的流程管理;又需要“内练一口气”,做到漏洞风险早预防。一方面需要加强人工智能网络安全漏洞的管理,建立人工智能漏洞资源库,规范漏洞发现、报送、披露和修复全流程,实现漏洞闭环管理。另一方面,要着力提高对漏洞后门的防御能力,建立健全风险监测、预警、通报和处置机制,完善威胁发现、攻击阻断、溯源等技术手段,及时发现风险、杜绝安全隐患。与此同时,还要注重以攻促防,积极打造认知域攻击武器,建立自己的人工智能系统和训练模型的漏洞库,对漏洞等战略资源进行有效储备,特别要加强跨语言、跨应用、跨平台、跨系统的共模漏洞挖掘,抢占“一招制敌”的关节点。
推进认知域安全技术范式创新
陈平研究员指出,建立“立体化”的防御体系,也只是权宜之计。从根本上应对认知域的安全威胁,破解“不可解释性”和“系统漏洞后门”,这两大安全命题,还需要推动认知域安全技术发展范式的创新。通过构造内生安全防御体系,使得具有认知能力的智能系统在“基因”层面具有内生安全功能,获得非特异性免疫能力。通俗的讲,就是打铁还需自身硬,认知安全的本质还是需要形成“认知免疫”能力。
对于认知域安全技术新范式,陈平研究员介绍到,在这方面的研究,我国目前处于领先状态。早在十年前,邬江兴院士就在全球率先提出了拟态防御理论,成功破解了网络安全、数字安全所面临的安全性与先进性、成熟性与可信性、自主性与开放性等诸多矛盾问题,在“供应链不安全”的限制条件下,保证开放条件下的数字空间安全可控;在“有毒带菌”的客观环境下,维护国家网络空间安全和关键信息基础设施的广义功能安全。就在刚刚落幕的数字中国建设展览会上,拟态防御技术被列为我国“十大硬核科技”。

图为科学出版社推出的《漫画拟态防御》,向公众普及网络空间、认知空间斗争的有关知识(王丹玉 供图)
认知域安全技术范式创新,将充分借鉴网络空间拟态防御技术的实现机理,以构建人工智能内生安全理论与技术体系为先导。人工智能内生安全技术范式的思维视角是“三域交织”,具体来说是“物理—信息—认知”三域相互交织,以开放而不是封闭作为人工智能安全的前提。方法论是通过相对正确公理的再发现,形成多模决策与反馈控制的逻辑表达,建立动态异构冗余构造和多智能体协同决策模型,来表达“已知的未知和未知的未知”,最终建立“认知免疫”能力。实践规范是将人工智能技术中的不确定性问题转化为一致性问题和可量化问题,从而实现各类认知系统的安全功能可量化设计、可验证度量,构建人工智能的广义鲁棒功能。
陈平研究员预测,在拟态技术理论的推动下,人工智能内生安全技术将成为维护认知域安全的“金钟罩”,将在数据安全、算法安全、模型安全的“立体化”、外挂式安全屏障的基础上,建立起基于“认知免疫”的内生安全防线,为推动认知域技术高质量发展和高水平安全提供有力支撑。
本文首发光明日报客户端,全媒体记者蔡侗辰,通讯员方仲礼

